TL;DR
| Parakeet V3 | Whisper Large V3 | |
|---|---|---|
| 速度 | 10× | 1× |
| 支持语种 | 25 | 100+ |
| 英语错误率 (WER) | 6.32% | 7.44% |
| 25 种语言平均错误率 (WER) | 12.0% | 12.6% |
| 幻觉 | 无 | 静音时产生 |
| 适用 | 英语和欧洲语言 | 亚洲、阿拉伯等语言 |
* 速度:35 分钟音频,Apple Silicon 实测。英语 WER:Open ASR Leaderboard。25 语言均值:FLEURS 基准测试。
从1.3.2版本开始,Mac 版 Whisper Notes 默认使用 NVIDIA Parakeet TDT 0.6B 作为语音引擎。英文转录速度比 Whisper Large V3 Turbo 快 10 倍,准确率也更高。如果你需要其他语言,Whisper 模型仍然可用。
为什么换了默认模型
Whisper 很好用,但它是个通用模型——支持 100 多种语言、能翻译、能生成时间戳,是把瑞士军刀。代价是速度。对于英文听写这种只需要快速出字的场景,它太重了。
最让我难受的是:按住 Fn 用全局语音输入时,说完大概1分钟的话,要等3到5秒才能看到转录结果。这个等待打断了节奏——你说完了,盯着光标,什么都没出来,voice typing 的魔力瞬间消失。
Parakeet 彻底改变了这一点。它的速度快到说完的瞬间,文字就出现了。言出法随,毫无延迟。一旦体验过这种感觉——这种丝滑的、零等待的流畅——就很难再回到 Whisper 了。
Parakeet V3 有多快?
数字最有说服力。同一台 Mac 上,同一段 35 分钟的音频:
| 模型 | 35 分钟音频 |
|---|---|
| Whisper Large V3 Turbo | 3 分钟 |
| Parakeet TDT 0.6B v3 | 18 秒 |
快了 10 倍。而且模型更小(6 亿 vs 8 亿参数),内存和电量消耗也更低。
Parakeet v3 为什么这么快
Whisper 处理音频的方式就像逐字朗读一本书——一帧一帧,从不跳过。即使是静音,它也在处理,在猜测下一个词是什么。这很严谨,但太慢了。
Parakeet 的思路完全不同。它先把音频信号压缩 8 倍,只保留关键信息。然后,它不再逐帧磨,而是同时预测两件事:你说了什么词,以及这个词持续多久——然后直接跳到下一个词。静音?直接跳过。一个长元音?一次预测搞定,而不是重复几十次。
结果就是,模型处理语音的方式更像你的大脑——只关注有意义的词,忽略中间的空白。这就是为什么它用更少的参数、更高的准确率,做到了 10 倍的速度。
基准测试:Parakeet v3 vs Whisper
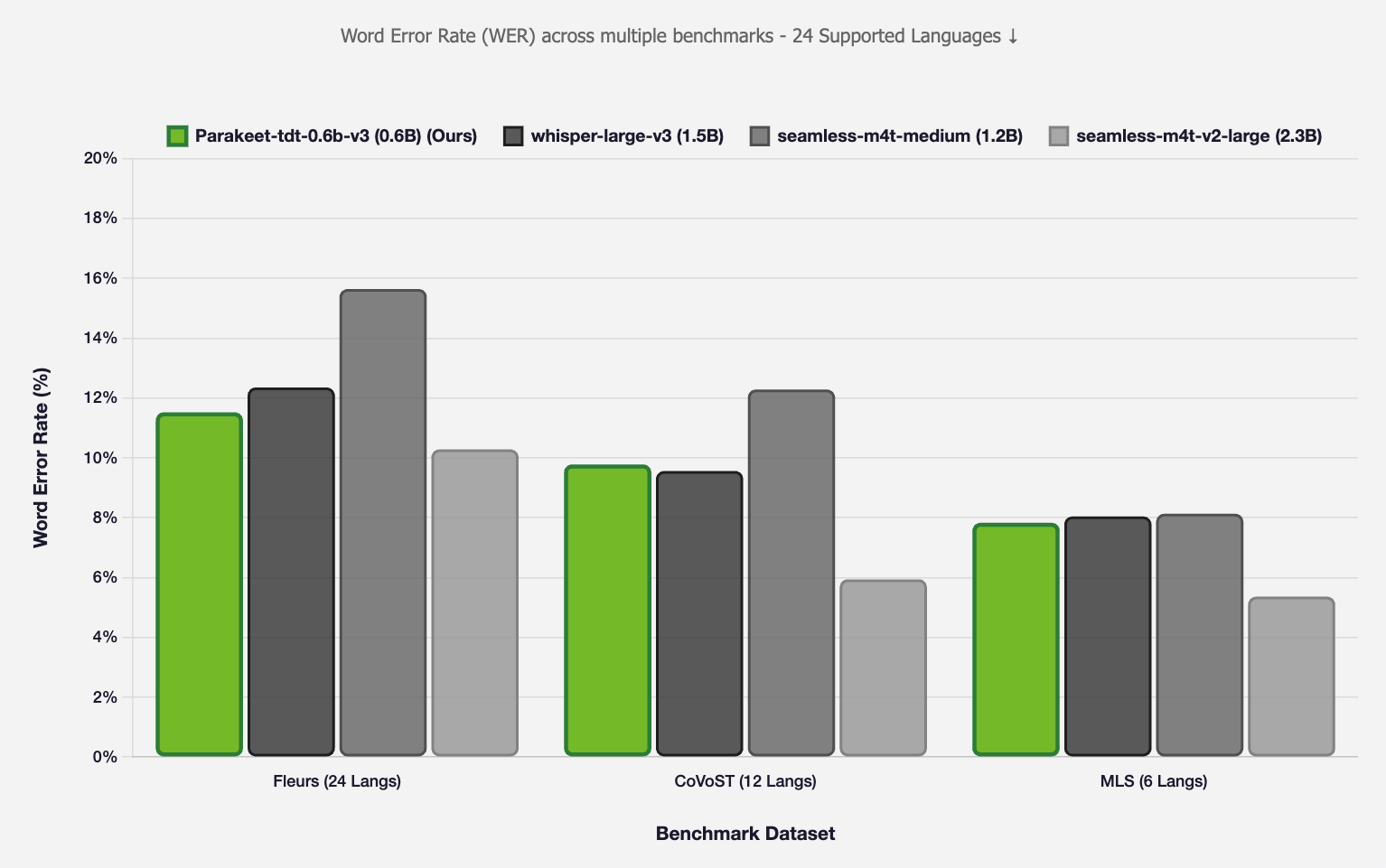
Parakeet v3 在 FLEURS、CoVoST 和 MLS 基准测试中匹敌甚至超越参数量 2-4 倍的模型
在 Hugging Face Open ASR 排行榜上,Parakeet v3 仅凭 6 亿参数就登顶——不到 Whisper Large V3 的 15.5 亿参数的一半:
| 模型 | 参数量 | 平均词错率 | 速度 (RTFx) |
|---|---|---|---|
| Parakeet TDT 0.6B v3 | 6 亿 | 6.32% | 3,333x |
| Canary 1B v2 | 10 亿 | 7.15% | 749x |
| Whisper Large V3 | 15.5 亿 | 7.44% | 146x |
| Whisper Large V3 Turbo | 8 亿 | 7.6% | 350x |
词错率越低越好,RTFx 越高越快。Parakeet 两项全赢。6 亿参数也意味着它是列表中最小的模型——在 Apple Silicon 上运行极其流畅,内存和电量消耗都很低。
多语言词错率:全部 25 种语言
上面的排行榜只涵盖英语。接下来是全貌——Whisper Notes 中可用的三个模型在 Parakeet 支持的全部 25 种语言上的表现,基于 FLEURS 基准测试。词错率越低 = 转录错误越少。每行中 Large V3 和 Parakeet 的最佳值已高亮显示:
| 语言 | Whisper Small | Whisper Large V3 | Parakeet V3 |
|---|---|---|---|
| 保加利亚语 | 37.3 | 12.9 | 12.6 |
| 克罗地亚语 | 33.4 | 11.1 | 12.5 |
| 捷克语 | 37.6 | 11.3 | 11.0 |
| 丹麦语 | 32.8 | 12.6 | 18.4 |
| 荷兰语 | 16.4 | 5.6 | 7.5 |
| 英语 | 6.1 | 4.3 | 4.9 |
| 爱沙尼亚语 | 51.3 | 19.1 | 17.7 |
| 芬兰语 | 24.0 | 7.7 | 13.2 |
| 法语 | 15.0 | 6.3 | 5.2 |
| 德语 | 10.2 | 4.3 | 5.0 |
| 希腊语 | 30.8 | 27.0 | 20.7 |
| 匈牙利语 | 38.9 | 14.1 | 15.7 |
| 意大利语 | 9.8 | 2.3 | 3.0 |
| 拉脱维亚语 | 53.2 | 18.3 | 22.8 |
| 立陶宛语 | 65.6 | 22.3 | 20.4 |
| 马耳他语 | 92.2 | 68.9 | 20.5 |
| 波兰语 | 14.7 | 4.7 | 7.3 |
| 葡萄牙语 | 7.3 | 3.7 | 4.8 |
| 罗马尼亚语 | 29.8 | 8.2 | 12.4 |
| 俄语 | 11.4 | 4.2 | 5.5 |
| 斯洛伐克语 | 33.3 | 8.4 | 8.8 |
| 斯洛文尼亚语 | 49.3 | 19.9 | 24.0 |
| 西班牙语 | 5.6 | 3.1 | 3.5 |
| 瑞典语 | 20.8 | 7.9 | 15.1 |
| 乌克兰语 | 19.3 | 6.5 | 6.8 |
| 平均 | 29.8 | 12.6 | 12.0 |
词错率(%)基于 FLEURS 测试集。Whisper Small 数据来自 Radford 等人;Large V3 和 Parakeet V3 数据来自 NVIDIA Canary-1B-v2 论文。
Whisper Large V3 在大多数单语言上略胜一筹——毕竟它的参数量是 Parakeet 的 2.5 倍。但 Parakeet V3 在平均值上与之持平(12.0% vs 12.6%),在希腊语、法语、爱沙尼亚语和马耳他语上大幅领先,且全面碾压 Whisper Small(平均减少 60% 的错误)。真正的重点不在于零点几个百分点的词错率差异——而在于综合实力:Large V3 级别的准确率,23 倍的速度,40% 的内存占用,零幻觉,全部在你的 Mac 上本地运行。
告别幻觉问题
如果你用 Whisper 做过听写,可能遇到过它在静音时产生幻觉——重复短语、凭空造词,甚至输出"Subtitles by Amara.org"这种莫名其妙的文字。这是因为 Whisper 的自回归解码器总是期望生成文本,即使根本没有内容可转录。
NVIDIA 用 36,000 小时的纯非语音音频(背景噪音、咳嗽、静音)训练了 Parakeet,目标输出全部设为空字符串。模型学会了什么是静默,并在无人说话时保持安静。对于系统级全局听写来说,这是根本性的改变——你停下来思考时,屏幕上不会再冒出乱码。
Parakeet 支持的语言
Parakeet v3 支持 25 种语言:保加利亚语、克罗地亚语、捷克语、丹麦语、荷兰语、英语、爱沙尼亚语、芬兰语、法语、德语、希腊语、匈牙利语、意大利语、拉脱维亚语、立陶宛语、马耳他语、波兰语、葡萄牙语、罗马尼亚语、俄语、斯洛伐克语、斯洛文尼亚语、西班牙语、瑞典语和乌克兰语。
基本覆盖了整个欧洲,但不支持中文、日文、韩文、阿拉伯语和印地语。所以我们保留了 Whisper 模型作为可下载选项。如果你用日语或中文听写,可以在模型选择器中切换到 Whisper Large V3 Turbo。对于英语和欧洲语言,Parakeet v3 就是更好的引擎。
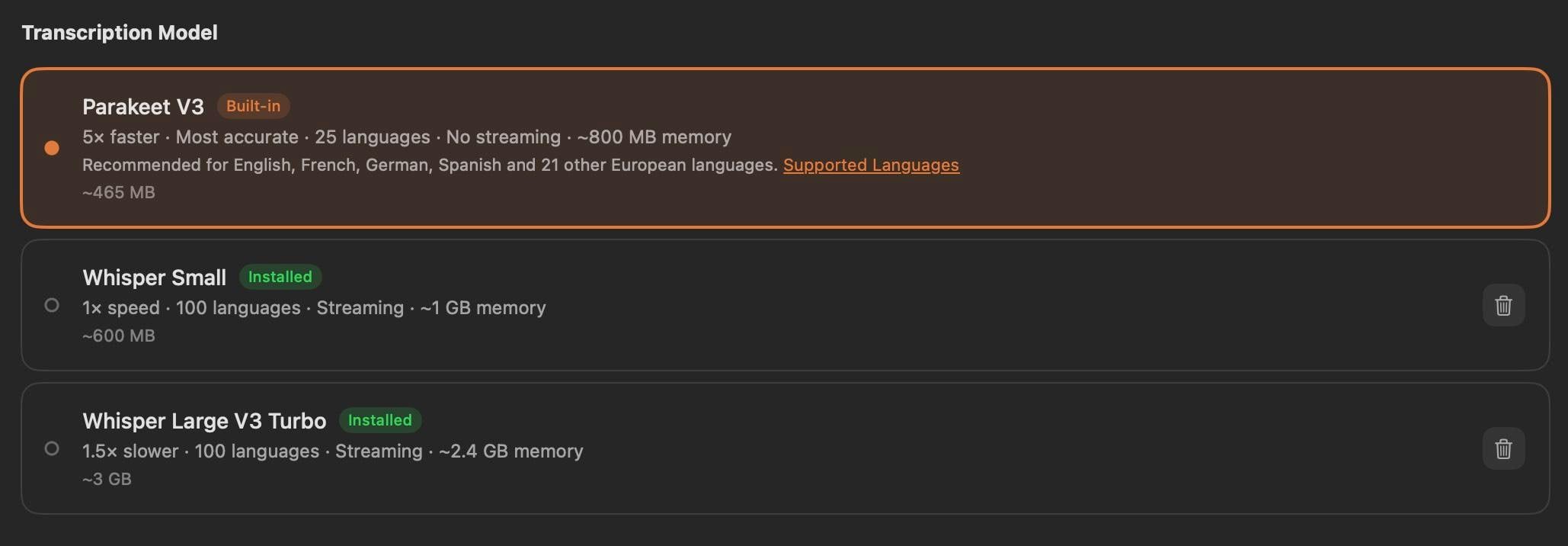
模型选择器:Parakeet V3(默认)、Whisper Small 和 Whisper Large V3 Turbo — 全部本地运行
Whisper Notes 中的模型选择器
打开设置即可切换模型:
- Parakeet V3(默认)— 最快,最适合英语和欧洲语言
- Whisper Small — 轻量级,支持 100+ 种语言
- Whisper Large V3 Turbo — 多语言最高精度模型
所有模型都在你的 Mac 上 100% 本地运行。无需联网,无需云端,数据不会离开你的设备。
Parakeet V2 怎么样?
如果你之前用过 V2,可能想知道它和 V3 有什么不同。V2 是纯英语模型,英语准确率实际上比 V3 略高(WER 6.05% vs 6.32%)。V3 用这一点点差距换来了 25 种语言的支持。不过两者都比 Whisper 准确得多。
| Parakeet V2 | Parakeet V3 | Whisper Large V3 | |
|---|---|---|---|
| 英语 WER | 6.05% | 6.32% | 7.44% |
| 支持语种 | 仅英语 | 25 | 100+ |
简单来说:如果你只需要英语,V2 和 V3 都很优秀。Whisper Notes 默认使用 V3,因为多语言支持对大多数用户更有价值——英语准确率的差异几乎可以忽略。
来试试
Parakeet v3 现已在 Mac 版中可用——直接下载最新 DMG 即可体验。(更新:最新版 iOS 已支持 Parakeet。)
有问题或反馈?邮件联系 support@whispernotes.app。